Kubernetes概述 Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。K8s 这个缩写是因为 K 和 s 之间有 8 个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验 的基础上, 结合了社区中最优秀的想法和实践。
什么是Kubernetes Kubernetes是一个可移植、可扩展的开源容器管理平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。Kubernetes拥有一个庞大且快速增长的生态系统。
它是由Google开发并开源的项目,现由云原生计算基金会(CNCF)维护,支持跨主机集群的容器化应用管理,提供负载均衡、自我修复、自动部署和存储编排等功能。
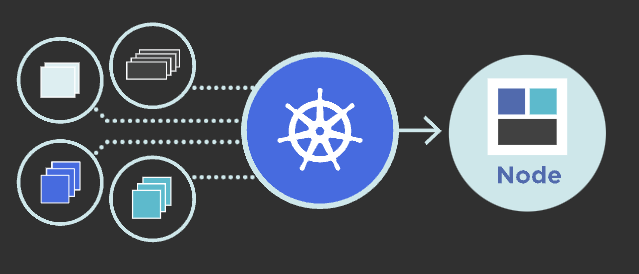
从Kubernetes的图标看,这个图标很像一艘船的船舵,控制着船行驶的方向。
再看docker的图标,类似一艘轮船(运行时),轮船上放着许多集装箱(容器),前面我们了解了一些docker的基础,现在我们要学习Kubernetes。
就好比原先你是一个吭哧吭哧打工搬运集装箱上船的员工,由于你的出色表现得到董事长的赏识,董事长把你从搬运工提升为掌舵的小领导,以后你再也不用亲历亲为去做具体的事情了,再也不用想着我要怎么把集装箱(容器)搬上船了,以后您只用下达指令你的监工们去替你督促和管理你的搬运工去做具体的事情,从此走上人生巅峰迎娶白富美。
Kubernetes的历史背景 让我们回顾一下为何 Kubernetes 能够裨益四方。
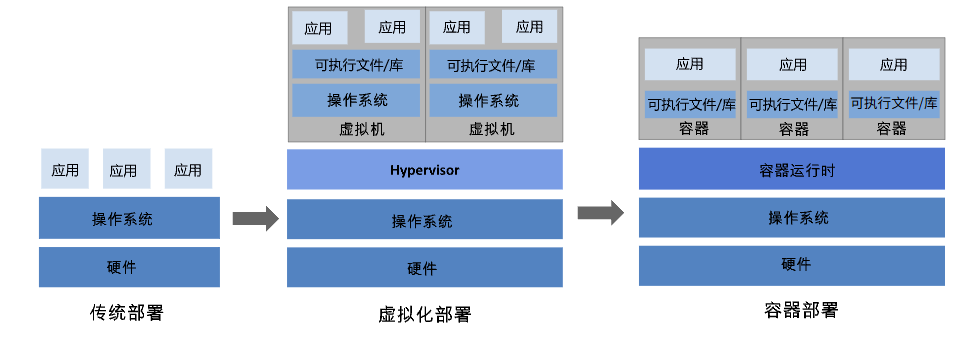
传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
资源隔离:可预测的应用程序性能。
资源利用:高效率和高密度。
Kubernetes特点 Kubernetes具有以下几个特点:
可移植:支持公有云、私有云、混合云、多重云(multi-cloud)
可扩展:模块化、插件化、可挂载、可组合
自动化:自动部署、自动修复、自动重启、自动复制、自动伸缩/扩展
Kubernetes作用 容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary (金丝雀) 部署。
Kubernetes 为你提供:
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
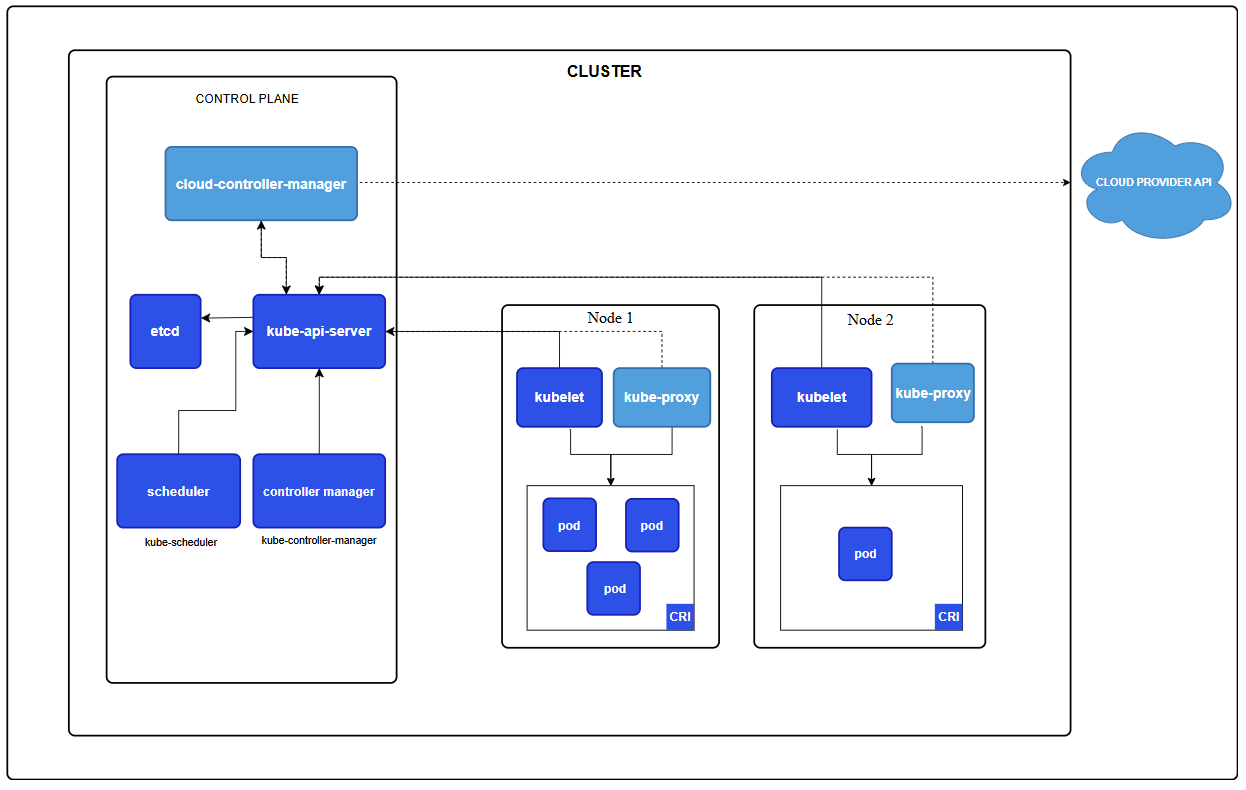
Kubernetes整体框架 Kubernetes 集群由一个控制平面和一组用于运行容器化应用的工作机器组成, 这些工作机器称作节点(Node)。每个集群至少需要一个工作节点来运行 Pod。
工作节点托管着组成应用负载的 Pod。控制平面管理集群中的工作节点和 Pod。 在生产环境中,控制平面通常跨多台计算机运行,而一个集群通常运行多个节点,以提供容错和高可用。
K8s整体需要至少一个Master节点和至少一个Node节点,所以要使用K8s我们至少需要两台服务器。
Master节点又称为控制平面,这里主要是我们的船长控制室也就是管理员的负责向Node节点下发指令的地方;Node节点也就是具体工人的工作室,Node节点同时会有一个监工小组长的角色(Kubelet),负责监督具体干活的Docker是否正在努力的工作。
使用Docker的时候我们指的是一个容器,而到了K8s这个概念变了,既然是集群,那么我们一个容器服务不能只有一个容器,不然达不到多负载、伸缩扩展的要求,例如一个nginx服务会生成多个容器,多个容器组成一个Pod的概念。
本文概述了构建一个完整且可运行的 Kubernetes 集群所需的各种组件。
控制平面组件 控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足 Deployment 的 replicas (一个Pod扩展容器的数量)字段时,要启动新的Pod。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,安装脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户的服务容器。
kube-apiserver API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。API 服务器是 Kubernetes 控制平面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平扩缩,也就是说,它可通过部署多个实例来进行扩缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量,这就是高级篇多Master节点实现高可用的K8s集群。
etcd 一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库,主要记录着集群中由多少个Pod现在分别部署在那几个Node节点中等等集群数据。
如果你的 Kubernetes 集群使用 etcd 作为其后台数据库, 请确保你针对这些数据有一份备份计划。
kube-scheduler kube-scheduler 是控制平面的组件, 负责监视新创建的、根据自身的算法来为容器服务指定Pod应该运行在哪个Node节点上为最适合的。选择节点来让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 及 Pods 集合的资源需求、软硬件及策略约束、 亲和性及反亲和性规范、数据位置、工作负载间的干扰及最后时限。
kube-controller-manager kube-controller-manager 是控制平面的组件, 负责运行控制器进程。
从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在同一个进程中运行。
控制器有许多不同类型。以下是一些例子:
Node 控制器:负责在节点出现故障时进行通知和响应
Job 控制器:监测代表一次性任务的 Job 对象,然后创建 Pod 来运行这些任务直至完成
EndpointSlice 控制器:填充 EndpointSlice 对象(以提供 Service 和 Pod 之间的链接)。
ServiceAccount 控制器:为新的命名空间创建默认的 ServiceAccount。
cloud-controller-manager 一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager)允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
cloud-controller-manager 仅运行特定于云平台的控制器。 因此如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的集群不包含云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的控制回路组合到同一个可执行文件中,以同一进程的方式供你运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
Node 控制器:用于在节点终止响应后检查云平台以确定节点是否已被删除
Route 控制器:用于在底层云基础架构中设置路由
Service 控制器:用于创建、更新和删除云平台上的负载均衡器
节点组件 节点组件会在每个Node节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行时环境。
kubelet kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod中。
kubelet接收一组通过各类机制提供给它的 PodSpec,确保这些 PodSpec 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-proxy(可选) kube-proxy是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service)概念的一部分。
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
如果你使用网络插件为 Service 实现本身的数据包转发, 并提供与 kube-proxy 等效的行为,那么你不需要在集群中的节点上运行 kube-proxy。
容器运行时 这个基础组件使 Kubernetes 能够有效运行容器。 它负责管理 Kubernetes 环境中容器的执行和生命周期。
Kubernetes 支持许多容器运行环境,例如 containerd、 CRI-O以及 Kubernetes CRI、CRI-docker (容器运行环境接口) 的其他任何实现。
Kubernetes常用插件 插件使用 Kubernetes 资源(DaemonSet、 Deployment 等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
Core-DNS 尽管该插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该有集群 DNS, 因为很多示例都需要 DNS 服务。
集群 DNS 是一个 DNS 服务器,和环境中的其他 DNS 服务器一起工作,它为 Kubernetes 服务提供 DNS 记录。
Kubernetes 启动的容器自动将此 DNS 服务器包含在其 DNS 搜索列表中。
Web 界面(仪表盘) Dashboard是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身,并进行故障排除。
容器资源监控 容器资源监控 将关于容器的一些常见的时序度量值保存到一个集中的数据库中,并提供浏览这些数据的界面。
集群层面日志 集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中, 这种集中日志存储提供搜索和浏览接口。
网络插件 网络插件是实现容器网络接口(CNI)规范的软件组件。它们负责为 Pod 分配 IP 地址,并使这些 Pod 能在集群内部相互通信。
部署Kubernetes 环境介绍
版本
操作系统 RedHat 9.4
节点数量 至少2,本示例为3
CPU 至少2核心,本示例为4核心
内存 至少2G,本实例为8G
磁盘 100G
网络 公网和内网均可,只要3台彼此能够互联
其他 各节点主机名、MAC地址、product_uuid不可重复,如果使用VMware虚拟机避免使用克隆
IP规划
节点名称
IP
Master-01
192.168.8.136
Node-01
192.168.8.137
Node-02
192.168.8.138
环境初始化 关闭Swap分区
需在三个节点都要执行关闭
1 2 [root@localhost ~]# swapoff -a [root@localhost ~]# sed -i 's/.*swap.*/#&/' /etc/fstab
开启iptables 检查桥接流量
需在三个节点都要执行开启
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@localhost ~]# cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF modprobe br_netfilter cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF ...忽略.... [root@localhost ~]# sudo sysctl --system * Applying /usr/lib/sysctl.d/10-default-yama-scope.conf ... ...忽略.... [root@localhost ~]# sysctl net.ipv4.ip_forward
配置主机名
需在三个节点都要执行配置,可根据自身需要自行定义主机名,各节点主机名不可重复,主机名需具有识别性。
1 2 3 4 5 6 [root@localhost ~]# hostnamectl hostname k8s-master-01 [root@localhost ~]# hostnamectl hostname k8s-node-01 [root@localhost ~]# hostnamectl hostname k8s-node-02
配置hosts域名解析
需在三个节点都要执行配置,写入参数需根据自身的IP和主机名进行调整。
1 2 3 4 5 6 cat >> /etc/hosts << EOF 192.168.8.136 k8s-master-01 192.168.8.137 k8s-node-01 192.168.8.138 k8s-node-02 192.168.8.135 reg.liweihu.cn EOF
部署运行时docker 这里我们采用的运行时是docker引擎,docker 引擎的部署我们在第一章已经介绍过了,可以参考第一章的【离线部署docker】进行部署。
我们本次采用的是docker,v1.24 之前的 Kubernetes 版本直接集成了 Docker引擎的一个组件,名为 dockershim 。但是之后的版本K8S将不在替Docker搞特殊去维护他的组件了,所以把这部分三方运行时接口删除,交给第三方docker自行去维护,docker之后就将这部分运行时接口改名为CRI-Docker ,所以我们只使用docker不需要他的CRI,如果想用docker作为K8S的运行时则必须要安装docker的CRI。
默认情况下,K8s使用容器运行时接口来与你所选择的容器运行时进行交互。
如果您在部署时不指定运行时,则Kubeadm会自动尝试检测您系统上已安装的运行时,方法是扫描众所周知的Unix域套接字。
运行时常用套接字
运行时
默认Linux中的套接字
cri-dockerd
/run/cri-dockerd.sock
containerd
/run/containerd/containerd.sock
CRI-O
/var/run/crio/crio.sock
CRI-Docker部署 CRI-Docker下载地址 :https://github.com/Mirantis/cri-dockerd/releases
CRI-Docker.service启动文件下载地址 :https://github.com/Mirantis/cri-dockerd/blob/master/packaging/systemd/cri-docker.service
cri-docker.socket启动文件下载地址 :https://github.com/Mirantis/cri-dockerd/blob/master/packaging/systemd/cri-docker.socket
解压压缩包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@k8s-master-01 softapp]# tar -zxvf /opt/softapp/cri-dockerd-0.4.0.amd64.tgz --strip-components=1 -C /usr/local/bin/ && chmod 775 /usr/local/bin/cri-dockerd [root@k8s-master-01 softapp]# chmod 775 /etc/systemd/system/cri-docker.service [root@k8s-master-01 softapp]# [root@k8s-master-01 softapp]# [root@k8s-master-01 softapp]#
创建systemd守护进程
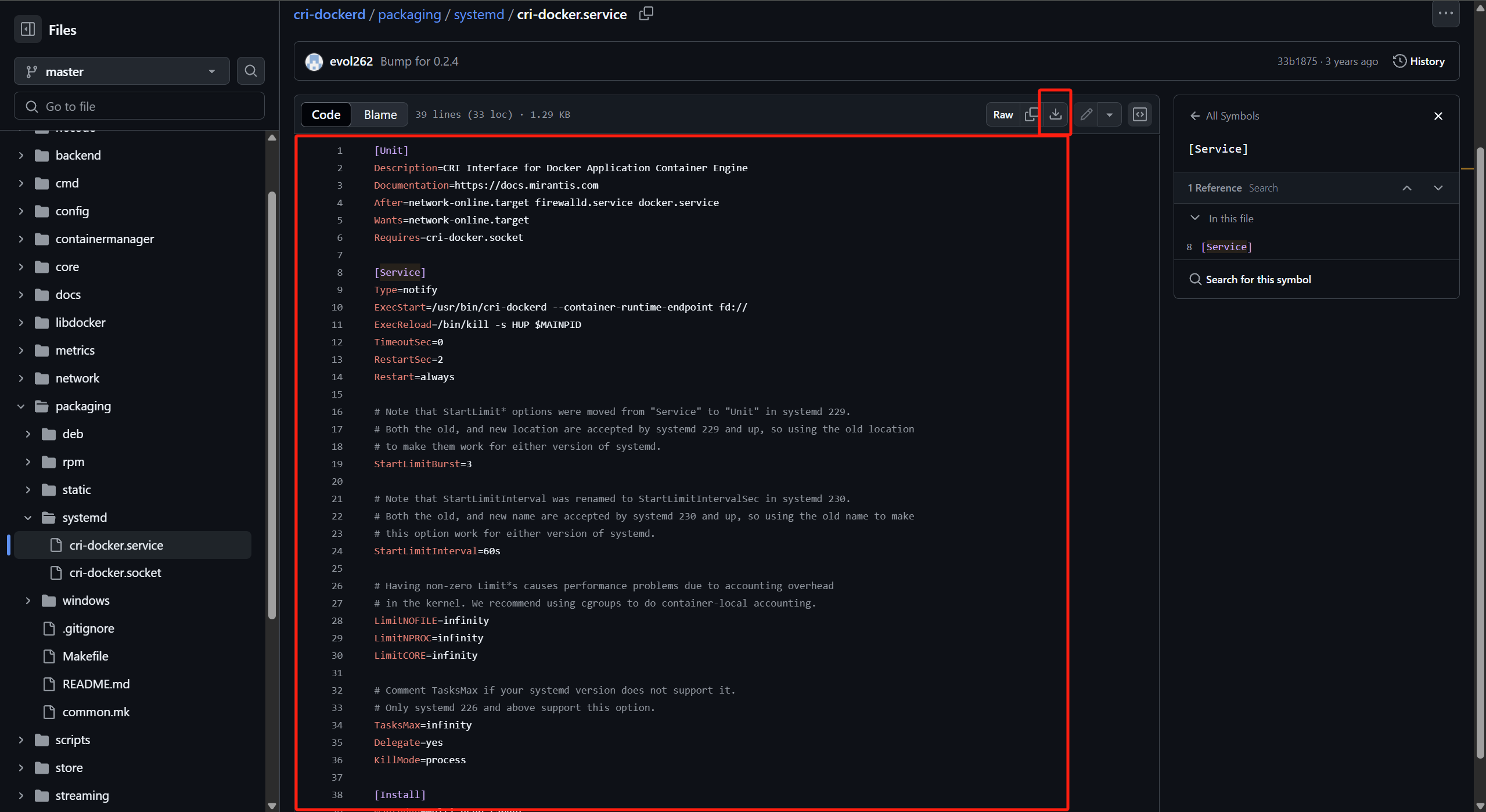
cri-docker.service 守护进程配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 [root@k8s-master-01 softapp]# cat > /etc/systemd/system/cri-docker.service << EOF [Unit] Description=CRI Interface for Docker Application Container Engine Documentation=https://docs.mirantis.com After=network-online.target firewalld.service docker.service Wants=network-online.target Requires=cri-docker.socket [Service] Type=notify ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// ExecReload=/bin/kill -s HUP $MAINPID TimeoutSec=0 RestartSec=2 Restart=always # Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229. # Both the old, and new location are accepted by systemd 229 and up, so using the old location # to make them work for either version of systemd. StartLimitBurst=3 # Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230. # Both the old, and new name are accepted by systemd 230 and up, so using the old name to make # this option work for either version of systemd. StartLimitInterval=60s # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Comment TasksMax if your systemd version does not support it. # Only systemd 226 and above support this option. TasksMax=infinity Delegate=yes KillMode=process [Install] WantedBy=multi-user.target EOF
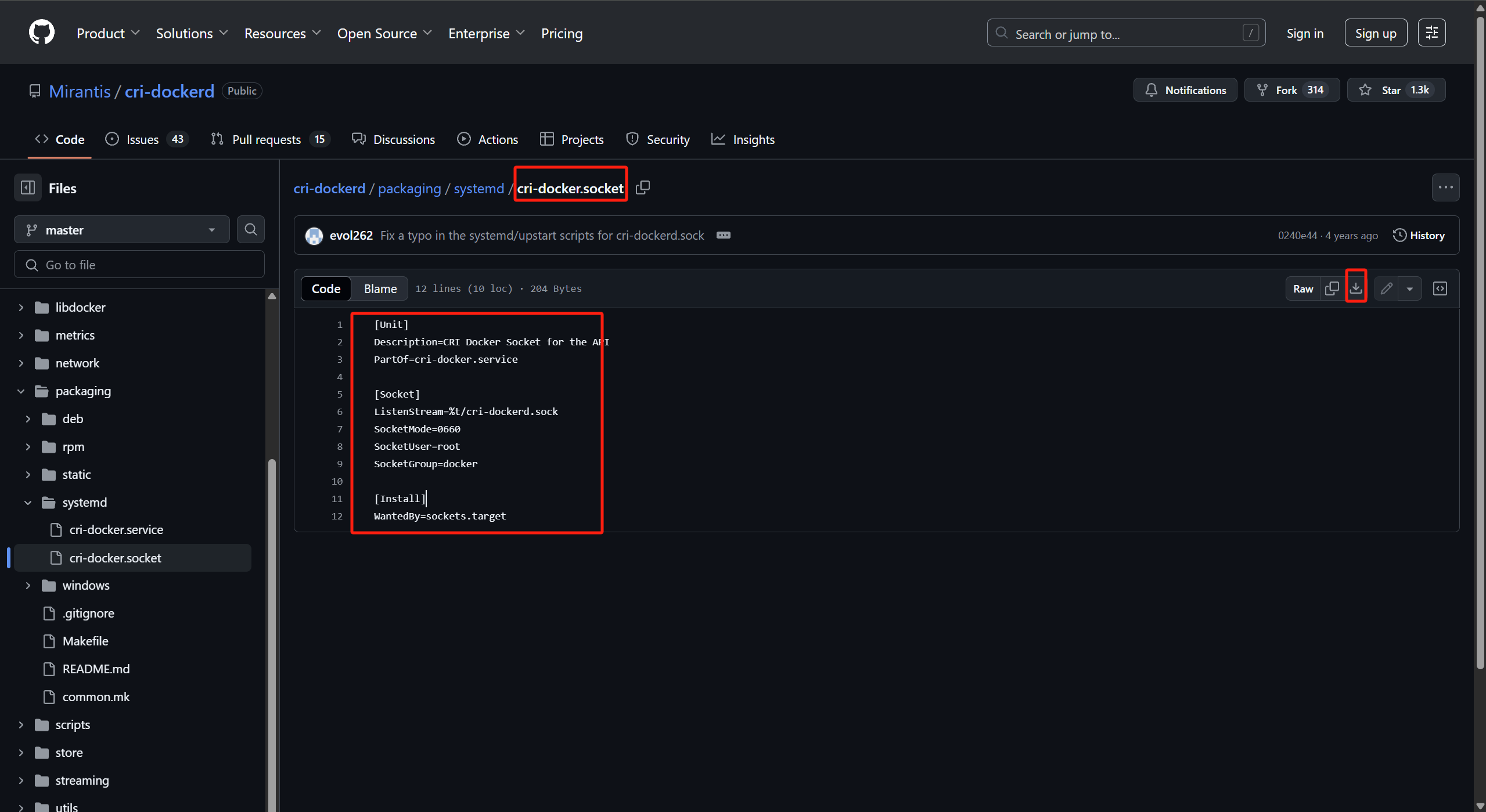
cri-docker.socket 守护进程配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@k8s-master-01 softapp]# cat > /etc/systemd/system/cri-docker.socket << EOF [Unit] Description=CRI Docker Socket for the API PartOf=cri-docker.service [Socket] ListenStream=%t/cri-dockerd.sock SocketMode=0660 SocketUser=root SocketGroup=docker [Install] WantedBy=sockets.target EOF
修改守护进程配置文件
1 2 3 4 5 [root@k8s-master-01 softapp]# sed -i -e 's,/usr/bin/cri-dockerd --container-runtime-endpoint fd://,/usr/local/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.liweihu.cn/google_containers/pause:3.10,' /etc/systemd/system/cri-docker.service [root@k8s-master-01 system]# sed -i -e 's,docker,root,' /etc/systemd/system/cri-docker.socket [root@k8s-master-01 system]# sed -i -e 's,%t/cri-rootd.sock,/run/cri-dockerd.sock,' /etc/systemd/system/cri-docker.socket
启动cri-docker
1 2 3 [root@k8s-master-01 system]# chmod 775 /etc/systemd/system/cri-docker.s* [root@k8s-master-01 system]# systemctl daemon-reload [root@k8s-master-01 system]# systemctl enable --now cri-docker.service
部署kubeadm、kubelet、kubect 下载地址:https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.33/rpm/x86_64/?spm=a2c6h.25603864.0.0.70ef7af3yMGs1u
分别把这五个软件包分别下载最新版本
kubeadm :用于初始化集群的工具包指令。kubelet :在集群中的每个节点上用来启动Pod和容器等。kubectl :用来与集群通信的命令行工具。cni :kubelet的依赖程序。tools :kubeadm的依赖程序
注意:您需要确保它们与通过kubeadm安装的控制平面版本相匹配。不然可能会导致一些预料之外的错误。然而控制平面与kubelet之间相差一个次要版本不一致是支持的,但kubelet的版本不可以超过API服务器的版本。例如1.7.0版本的kubelet可以兼容1.8.0本版本的API,1.8.0的API不能兼容1.7.0的kubelet。
所以为了避免出现不可预料的问题,还是建议尽量所有组件统一版本。
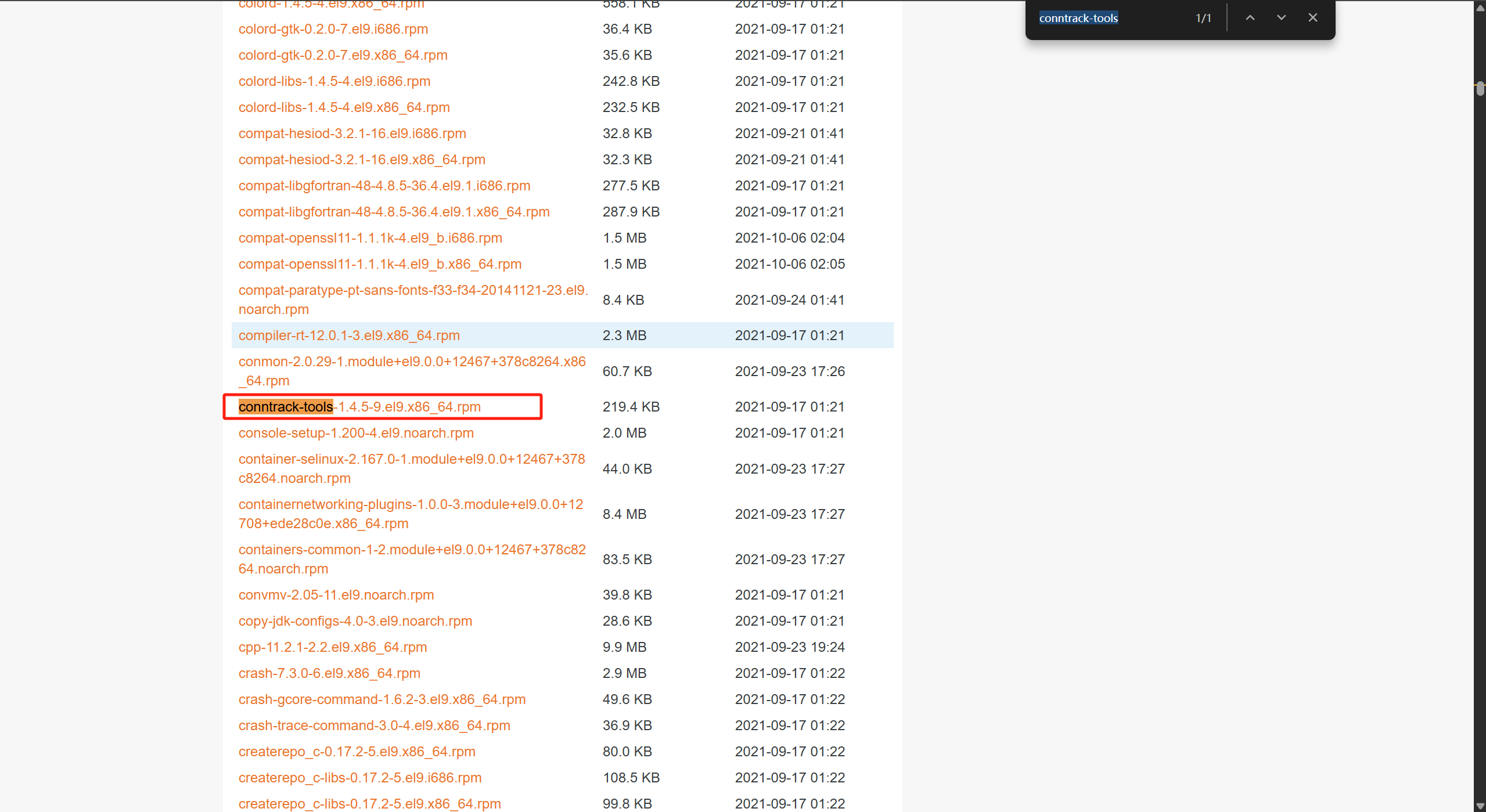
conntrack-tools及相关依赖下载地址 :https://mirrors.aliyun.com/redhat/rhel/rhel-9-beta/appstream/x86_64/Packages/?spm=a2c6h.25603864.0.0.6192773eKiz0x9
同一下载界面需要下载以下软件包:libnetfilter_cthelper、libnetfilter_cttimeout、libnetfilter_queue,例如下图,通过浏览器CTRL+F进行搜索下载
部署相关组件 软件包下载并上传至三个节点,最后一次按照顺序执行rpm安装程序。
1 2 3 4 5 6 [root@k8s-master-01 softapp]# rpm -ivh libnetfilter*.rpm [root@k8s-master-01 softapp]# rpm -ivh conntrack-tools-1.4.5-9.el9.x86_64.rpm [root@k8s-master-01 softapp]# rpm -ivh kubernetes-cni-1.6.0-150500.1.1.x86_64.rpm cri-tools-1.33.0-150500.1.1.x86_64.rpm [root@k8s-master-01 softapp]# rpm -ivh kubeadm-1.33.2-150500.1.1.x86_64.rpm kubectl-1.33.2-150500.1.1.x86_64.rpm kubelet-1.33.2-150500.1.1.x86_64.rpm [root@k8s-master-01 softapp]# systemctl enable --now kubelet.service
验证kubeadm、kubelet、kubectl版本
1 2 3 [root@k8s-master-01 softapp]# kubeadm version [root@k8s-master-01 softapp]# kubectl version [root@k8s-master-01 softapp]# kubelet --version
添加命令补全功能
1 2 3 4 [root@k8s-master-01 softapp]# kubectl completion bash > /etc/bash_completion.d/kubectl [root@k8s-master-01 softapp]# kubeadm completion bash > /etc/bash_completion.d/kubeadm [root@k8s-master-01 softapp]# source /etc/bash_completion.d/kubectl [root@k8s-master-01 softapp]# source /etc/bash_completion.d/kubeadm
初始化集群 通过具有外网的Habor主机拉取所需镜像,如果您的Harbor不具备外网,则可以先使用您具备外网的docker将镜像拉取到本地,然后通过docker save和docker load将镜像保存成tar文件再导入进您的Harbor主机中。
拉取镜像
harbor主机上执行拉取镜像的任务
1 2 3 4 5 6 7 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.33.0 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.33.0 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.33.0 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.33.0 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/etcd:3.5.21-0 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/pause:3.10 [root@reg ~]# docker pull registry.aliyuncs.com/google_containers/coredns:v1.12.0
为镜像重新打上新的标签
1 2 3 4 5 6 7 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.33.0 reg.liweihu.cn/google_containers/kube-apiserver:v1.33.0 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.33.0 reg.liweihu.cn/google_containers/kube-proxy:v1.33.0 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.33.0 reg.liweihu.cn/google_containers/kube-controller-manager:v1.33.0 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.33.0 reg.liweihu.cn/google_containers/kube-scheduler:v1.33.0 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/etcd:3.5.21-0 reg.liweihu.cn/google_containers/etcd:3.5.21-0 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/pause:3.10 reg.liweihu.cn/google_containers/pause:3.10 [root@reg ~]# docker tag registry.aliyuncs.com/google_containers/coredns:v1.12.0 reg.liweihu.cn/google_containers/coredns:v1.12.0
上传Harbor仓库
1 2 3 4 5 6 7 [root@reg ~]# docker push reg.liweihu.cn/google_containers/kube-apiserver:v1.33.0 [root@reg ~]# docker push reg.liweihu.cn/google_containers/kube-scheduler:v1.33.0 [root@reg ~]# docker push reg.liweihu.cn/google_containers/kube-controller-manager:v1.33.0 [root@reg ~]# docker push reg.liweihu.cn/google_containers/kube-proxy:v1.33.0 [root@reg ~]# docker push reg.liweihu.cn/google_containers/etcd:3.5.21-0 [root@reg ~]# docker push reg.liweihu.cn/google_containers/pause:3.10 [root@reg ~]# docker push reg.liweihu.cn/google_containers/coredns:v1.12.0
Master节点集群初始化 Master节点上执行,他会为您将仓库中的K8s镜像拉到本地,然后为您的集群制作证书等初始化配置。
初始化完成后,输出的信息一定要保存好,这个非常重要,我们需要用它输出的命令来完成最后的操作,以及node节点的加入集群。
参数解析
–apiserver-advertise-address :Master节点IP–apiserver-bind-port :Master中的API端口–kubernetes-version :k8s版本–cri-socket :运行时的sock文件路径–service-dns-domain :dns域–image-repository :镜像仓库地址–service-cidr :service服务发现网段–pod-network-cidr :pod网段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [root@k8s-master-01 etc]# kubeadm init \ --apiserver-advertise-address=192.168.8.136 \ --apiserver-bind-port=6443 \ --kubernetes-version=1.33.0 \ --token-ttl=0 \ --cri-socket=/run/cri-dockerd.sock \ --service-dns-domain=cluster.local \ --image-repository reg.liweihu.cn/google_containers \ --service-cidr=10.96.0.0/12 \ --pod-network-cidr=10.244.0.0/16 [init] Using Kubernetes version: v1.33.0 [preflight] Running pre-flight checks [WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" ......忽略..... Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.8.136:6443 --token 6v7c7k.9hc5wow978c3xkbx \ --discovery-token-ca-cert-hash sha256:5b2af6b3c07f793f1f863203624d26c187bbc425b12de797616bf9fbbc3bed4c
根据输出的提示,Master节点执行它提供的命令
1 2 3 4 5 6 [root@k8s-master-01 etc]# mkdir -p $HOME /.kube [root@k8s-master-01 etc]# sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config [root@k8s-master-01 etc]# sudo chown $(id -u):$(id -g) $HOME /.kube/config [root@k8s-master-01 etc]# export KUBECONFIG=/etc/kubernetes/admin.conf
执行完成后,我们可以先认识一下kubectl get nodes这条命令,该命令的作用是查看集群下分别由哪些节点,以及各节点的角色、状态、版本等。
kubectl为k8s控制集群的命令。get获取,nodes节点。可以看到当前就只有一个控制平面的节点,并且他的状态是NotReady(未启动的)。
1 2 3 [root@k8s-master-01 etc]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 NotReady control-plane 14m v1.33.2
创建secret Secret是k8s中非常使用的一个功能,例如我们在初始化集群的时候我们把存放K8s镜像的仓库,设置为私有镜像
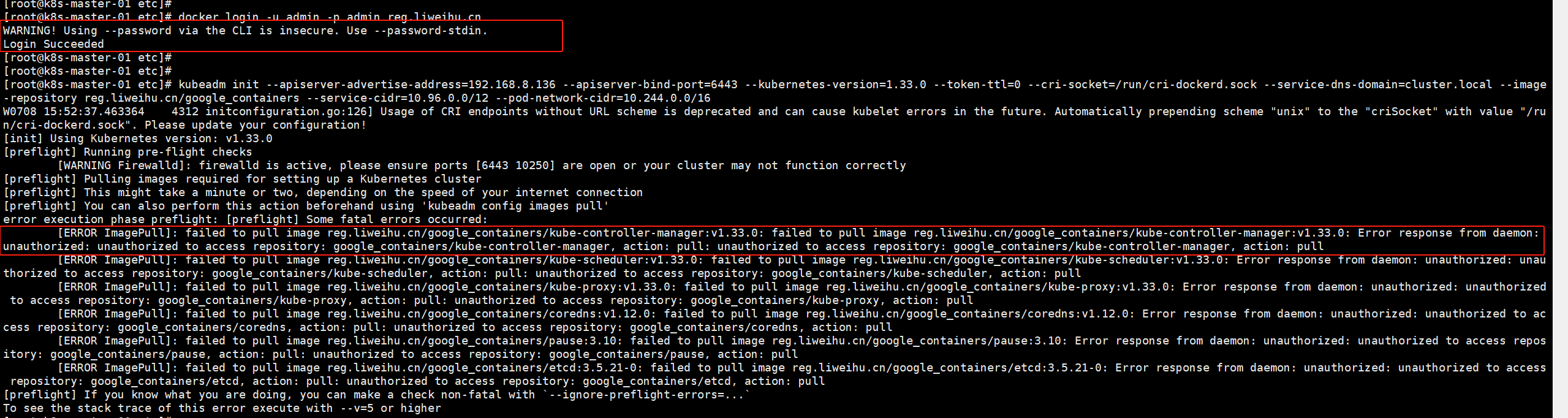
当我们进行初始化kubeadm的时候提示就会提示如下图的错误,拉取镜像失败,仓库是未经授权的错误,但是我们docke login和pull都能正常从这个私有仓库拉镜像下来,那是因为我们在docker login的时候是用了admin这个用户去登录的,docker使用了管理员用户,他肯定是可以拉下来的,但是我们的kubeadm使用的可不一定是管理员,所以造成这样的异常,这里我们可以把仓库设置为公开即可。
如果我们公司内部为了安全的保护内部镜像不被泄露,在k8s创建pod从私有仓库拉还是会遇到这样的问题,那这个时候我们就要介绍一下K8s中的Secret资源了。
创建Secret
命令解析:
kubectl :为控制集群的二进制命令。create :表示该操作为创建某个资源。secret :创建的资源类型为secret的选项。docker-registry :该资源下的子类别,用于docker仓库的选项。registry-secret-liweihu :资源名称参数。docker-server :仓库地址参数。docker-username :仓库的用户名参数。docker-password :仓库的密码参数
1 2 3 4 5 6 7 [root@k8s-master-01 etc]# kubectl create secret docker-registry registry-secret-liweihu --docker-server=reg.liweihu.cn --docker-username=admin --docker-password=admin secret/registry-secret-liweihu created [root@k8s-master-01 etc]# kubectl get secrets NAME TYPE DATA AGE registry-secret-liweihu kubernetes.io/dockerconfigjson 1 17s [root@k8s-master-01 etc]#
这样就创建完成了,这个验证我们到后面章节再为大家展示创建与没创建的效果,本章节了解该内容即可,便于后续的操作。
将Node节点添加至集群中 前面我们创建了集群,目前集群里仅有一个控制平面节点(Master),接下来我们要将Node节点加入集群,这里要使用到我们初始化集群时保存的如下命令再node节点进行操作,添加节点。
两个节点执行的命令都是一样的,依次有序执行即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@k8s-node-01 system]# kubeadm join 192.168.8.136:6443 --token 6v7c7k.9hc5wow978c3xkbx --discovery-token-ca-cert-hash sha256:5b2af6b3c07f793f1f863203624d26c187bbc425b12de797616bf9fbbc3bed4c [preflight] Running pre-flight checks [preflight] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system" ... [preflight] Use 'kubeadm init phase upload-config --config your-config-file' to re-upload it. [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s [kubelet-check] The kubelet is healthy after 1.503844186s [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. [root@k8s-node-01 system]#
添加完成后,我们再回来Master节点,查看集群节点就可以看到另外两台node已经现实出来了。
1 2 3 4 5 [root@k8s-master-01 etc]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 NotReady control-plane 137m v1.33.2 k8s-node-01 NotReady <none> 5m40s v1.33.2 k8s-node-02 NotReady <none> 43s v1.33.2
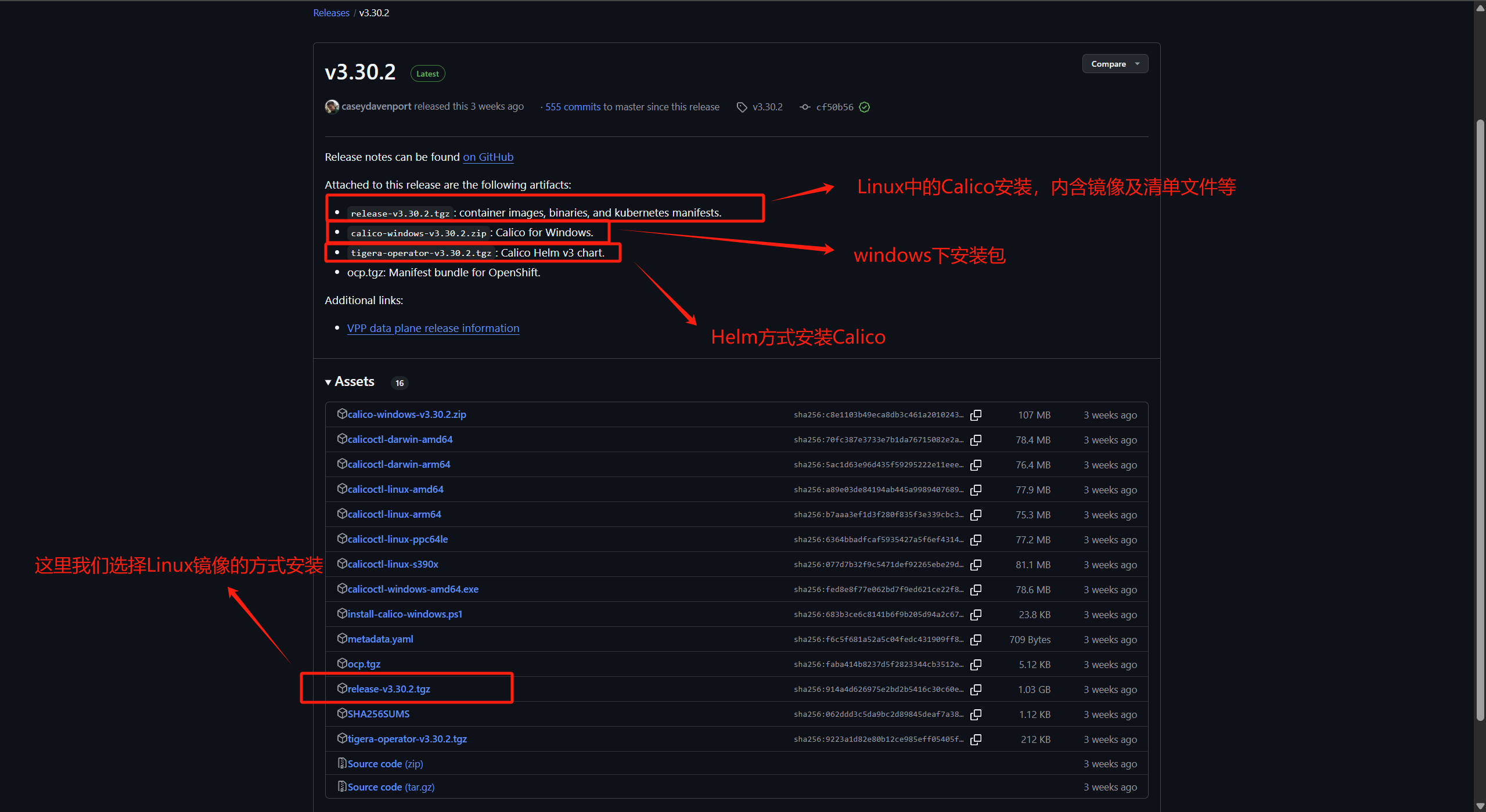
Calico网络部署 软件包下载 下载地址: https://github.com/projectcalico/calico/releases/tag/v3.30.2
上传并部署Calico 解压完成后,进入解压目录中的images目录,将里面的镜像文件导入到本地镜像仓库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@k8s-master-01 images]# pwd /opt/softapp/release-v3.30.2/images [root@k8s-master-01 images]# ll 总用量 1007816 -rw-------. 1 1001 1001 162432000 6月 20 06:57 calico-cni.tar -rw-------. 1 1001 1001 91260416 6月 20 06:57 calico-dikastes.tar -rw-------. 1 1001 1001 152131072 6月 20 06:57 calico-flannel-migration-controller.tar -rw-------. 1 1001 1001 121548288 6月 20 06:57 calico-kube-controllers.tar -rw-------. 1 1001 1001 407298560 6月 20 06:57 calico-node.tar -rw-------. 1 1001 1001 12103168 6月 20 06:57 calico-pod2daemon.tar -rw-------. 1 1001 1001 85215744 6月 20 06:57 calico-typha.tar [root@k8s-master-01 images]# docker load -i calico-cni.tar [root@k8s-master-01 images]# docker load -i calico-dikastes.tar [root@k8s-master-01 images]# docker load -i calico-flannel-migration-controller.tar [root@k8s-master-01 images]# docker load -i calico-kube-controllers.tar [root@k8s-master-01 images]# docker load -i calico-node.tar [root@k8s-master-01 images]# docker load -i calico-pod2daemon.tar [root@k8s-master-01 images]# docker load -i calico-typha.tar [root@k8s-master-01 images]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE calico/typha v3.30.2 b3baa600c7ff 3 weeks ago 85.2MB calico/pod2daemon-flexvol v3.30.2 639615519fa6 3 weeks ago 12MB calico/node v3.30.2 cc52550d767f 3 weeks ago 405MB calico/flannel-migration-controller v3.30.2 0f62b640dd7c 3 weeks ago 152MB calico/kube-controllers v3.30.2 761b294e2655 3 weeks ago 122MB calico/cni v3.30.2 77a357d0d33e 3 weeks ago 162MB calico/dikastes v3.30.2 b3e1c212267f 3 weeks ago 91.2MB
为导入进本地镜像仓库的calico镜像重新打上新标签,便于上传Harbor私有镜像仓库。
1 2 3 4 5 6 7 8 [root@k8s-master-01 manifests]# docker tag calico/cni:v3.30.2 reg.liweihu.cn/calico/cni:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/node:v3.30.2 reg.liweihu.cn/calico/node:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/kube-controllers:v3.30.2 reg.liweihu.cn/calico/kube-controllers:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/pod2daemon-flexvol:v3.30.2 reg.liweihu.cn/calico/pod2daemon-flexvol:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/dikastes:v3.30.2 reg.liweihu.cn/calico/dikastes:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/typha:v3.30.2 reg.liweihu.cn/calico/typha:v3.30.2 [root@k8s-master-01 manifests]# docker tag calico/flannel-migration-controller:v3.30.2 reg.liweihu.cn/calico/flannel-migration-controller:v3.30.2
将重新打好标签的镜像上传本地镜像仓库,在此操作前,需先在Harbor创建好一个公开的calico仓库,仓库名称具体根据你的标签定义的仓库名称来自行定于。
标签组成解析
reg.liweihu.cn/:镜像仓库地址(域名)
calico/:仓库名称
cni:v3.30.2:镜像名:版本号
1 2 3 4 5 6 7 8 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/cni:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/node:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/kube-controllers:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/pod2daemon-flexvol:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/dikastes:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/typha:v3.30.2 [root@k8s-master-01 manifests]# docker push reg.liweihu.cn/calico/flannel-migration-controller:v3.30.2
进入到软件包解压后的manifests目录,修改yaml文件镜像拉取的地址,默认是dockerHub的公有镜像仓库,但是由于限制的问题,我们无法从国内获取,所以需要离线从我们的私有仓库中获取镜像。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [root@k8s-master-01 manifests]# pwd /opt/softapp/release-v3.30.2/manifests [root@k8s-master-01 manifests]# cat calico.yaml |grep image: image: docker.io/calico/cni:v3.30.2 image: docker.io/calico/cni:v3.30.2 image: docker.io/calico/node:v3.30.2 image: docker.io/calico/node:v3.30.2 image: docker.io/calico/kube-controllers:v3.30.2 [root@k8s-master-01 manifests]# cat calico.yaml |grep image: image: reg.liweihu.cn/calico/cni:v3.30.2 image: reg.liweihu.cn/calico/cni:v3.30.2 image: reg.liweihu.cn/calico/node:v3.30.2 image: reg.liweihu.cn/calico/node:v3.30.2 image: reg.liweihu.cn/calico/kube-controllers:v3.30.2 [root@k8s-master-01 manifests]# cat custom-resources.yaml | grep cidr: cidr: 10.244.0.0/16 [root@k8s-master-01 manifests]# kubectl apply -f custom-resources.yaml [root@k8s-master-01 manifests]# kubectl apply -f tigera-operator.yaml [root@k8s-master-01 manifests]# kubectl apply -f calico.yaml poddisruptionbudget.policy/calico-kube-controllers created serviceaccount/calico-kube-controllers created serviceaccount/calico-node created serviceaccount/calico-cni-plugin created configmap/calico-config created ....忽略.... clusterrole.rbac.authorization.k8s.io/calico-node created clusterrole.rbac.authorization.k8s.io/calico-cni-plugin created clusterrole.rbac.authorization.k8s.io/calico-tier-getter created clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created clusterrolebinding.rbac.authorization.k8s.io/calico-node created clusterrolebinding.rbac.authorization.k8s.io/calico-cni-plugin created clusterrolebinding.rbac.authorization.k8s.io/calico-tier-getter created daemonset.apps/calico-node created deployment.apps/calico-kube-controllers created
安装完成calico后,检查各节点是否处于Ready允许状态。
1 2 3 4 5 [root@k8s-master-01 manifests]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 Ready control-plane 3d1h v1.33.2 k8s-node-01 Ready <none> 2d23h v1.33.2 k8s-node-02 Ready <none> 2d23h v1.33.2
检查所有Pod是否运行正常,这里我们可以看到,以及calico为这些Pod分配的IP。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-master-01 manifests]# kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system calico-kube-controllers-7f59498f59-kf5nn 1/1 Running 2 (24m ago) 24h 10.244.151.136 k8s-master-01 <none> <none> kube-system calico-node-7ndvs 1/1 Running 2 (24m ago) 24h 192.168.8.137 k8s-node-01 <none> <none> kube-system calico-node-l4rfm 1/1 Running 2 (24m ago) 24h 192.168.8.136 k8s-master-01 <none> <none> kube-system calico-node-ls56h 1/1 Running 2 (24m ago) 24h 192.168.8.138 k8s-node-02 <none> <none> kube-system coredns-dc6b59956-72kvq 1/1 Running 2 (24m ago) 3d1h 10.244.151.135 k8s-master-01 <none> <none> kube-system coredns-dc6b59956-bfgfb 1/1 Running 2 (24m ago) 3d1h 10.244.151.137 k8s-master-01 <none> <none> kube-system etcd-k8s-master-01 1/1 Running 4 (24m ago) 3d1h 192.168.8.136 k8s-master-01 <none> <none> kube-system kube-apiserver-k8s-master-01 1/1 Running 4 (24m ago) 3d1h 192.168.8.136 k8s-master-01 <none> <none> kube-system kube-controller-manager-k8s-master-01 1/1 Running 4 (24m ago) 3d1h 192.168.8.136 k8s-master-01 <none> <none> kube-system kube-proxy-ggxph 1/1 Running 3 (24m ago) 2d23h 192.168.8.138 k8s-node-02 <none> <none> kube-system kube-proxy-hb9dg 1/1 Running 3 (24m ago) 2d23h 192.168.8.137 k8s-node-01 <none> <none> kube-system kube-proxy-rv6rk 1/1 Running 4 (24m ago) 3d1h 192.168.8.136 k8s-master-01 <none> <none> kube-system kube-scheduler-k8s-master-01 1/1 Running 4 (24m ago) 3d1h 192.168.8.136 k8s-master-01 <none> <none>
为Node节点打标签 我们部署完成后发现,我们的master节点是具有control-plane(控制平面)的角色标签,但是我们另外的两个node是none(空),为了便于管理辨认最好将其打上标签,已区分各节点的角色关系。
1 2 3 4 5 6 7 [root@k8s-master-01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 Ready control-plane 5d18h v1.33.2 k8s-node-01 Ready node 5d16h v1.33.2 k8s-node-02 Ready node 5d16h v1.33.2 [root@k8s-master-01 ~]# kubectl label nodes k8s-node-01 k8s-node-02 node-role.kubernetes.io/node=
加入Node节点 如果后续2台node已经支撑不了业务的运行,需要增加node节点,但是最开始的加入集群的语句已经丢了,我们可以通过一下方式获取新的join参数。
1 2 3 [root@k8s-master-01 ~]# kubeadm token create --print-join-command kubeadm join 192.168.8.136:6443 --token fuag1e.rlwcwz93roobuts8 --discovery-token-ca-cert-hash sha256:5b2af6b3c07f793f1f863203624d26c187bbc425b12de797616bf9fbbc3bed4cxxxxxxxxxx kubeadm token create --print-join-command[root@k8s-master-01 ~]# kubeadm token create --print-join-commandkubeadm join 192.168.8.136:6443 --token fuag1e.rlwcwz93roobuts8 --discovery-token-ca-cert-hash sha256:5b2af6b3c07f793f1f863203624d26c187bbc425b12de797616bf9fbbc3bed4cbash
重置集群 如果因为某种原因您想删除集群重新进行部署,可通过一下方式进行删除,删除完成后即可重新进行初始化集群。
1 2 3 4 5 6 [root@k8s-master-01 ~]# kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock [root@k8s-master-01 ~]# rm -rf /etc/cni/net.d [root@k8s-master-01 ~]# iptables -F [root@k8s-master-01 ~]# rm -rf $HOME /.kube/config
至此Kubernetes单节点集群已部署完成,离线部署话可以通过二进制的方式进行部署,所有组件通过守护进程进行管理,如果想了解二进制方式的部署可参考我的CSDN文档: https://blog.csdn.net/qq_42658764/article/details/137954292





 wechat
wechat alipay
alipay

